9:00 - 5:00
Mon - Fri
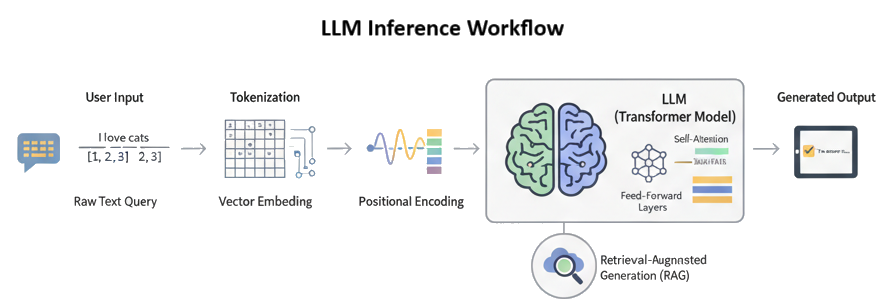
This phase focuses on converting unstructured data into a standardized, machine-readable format.
Identification of knowledge assets, including PDFs, websites, Notion documents, and internal APIs.
Extraction of raw text using specialized libraries such as Unstructured.io, BeautifulSoup, or PyMuPDF.
Data cleaning procedures including HTML tag removal, whitespace normalization, and encoding standardizations.
Segmentation of text into semantically meaningful units using recursive or semantic splitting to maintain context.
This phase transforms text into mathematical representations for high-speed retrieval.
Assigning identifiers to each chunk, such as Document ID, Section Name, and Timestamps, to enable filtered searching.
Converting text chunks into high-dimensional vectors using models like OpenAI (text-embedding-3-small) or Cohere.
Storing embeddings in specialized vector databases (e.g., Pinecone, ChromaDB, or Weaviate) for efficient similarity lookups.
Configuring database distance metrics (like Cosine Similarity) and hybrid search filters to ensure retrieval accuracy.
The system identifies the most relevant information based on a user’s specific request.
Processing the user's natural language input, including optional rephrasing or expansion via an LLM.
Converting the user's question into a vector using the same model applied to the original document chunks.
Executing a mathematical search to find the "Top-K" most relevant chunks from the vector store.
(Optional) Utilizing cross-encoders to re-rank retrieved chunks based on confidence, recency, or specific keyword matches.
The final phase synthesizes the retrieved information into a coherent human response.
Assembling a "contextual prompt" that includes the retrieved chunks, system instructions, and the user’s original query.
Sending the prompt to a Large Language Model (like GPT-4o, Claude 3, or Llama 3) to generate a response grounded in the provided data.
(Optional) Formatting the final response, adding source citations, or delivering the result via UI or API.
We don't just store your data; we make it work for you. By implementing a Retrieval-Augmented Generation (RAG) pipeline, EdexCloud ensures your Workers' Comp and legal queries are answered with surgical precision.
Feature |
Traditional Search |
EdexCloud RAG |
|---|---|---|
| Accuracy | Matches keywords only | Understands legal/medical context |
| Reliability | Prone to AI "hallucinations" | Grounded in your private documents |
| Speed | Manual sorting required | Instant synthesis of thousands of pages |
| Verification | No clear source trail | Direct citations to original PDF pages |
