9:00 - 5:00
Mon - Fri
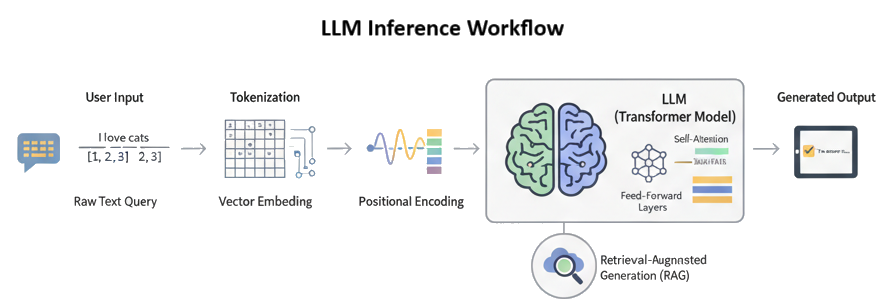
Before we understand how LLM works internally, let’s have a quick overview of GPT. GPT stands for Generative Pre-Trained Transformer.
Let’s understand further.
This is the initial stage where the user's plain-text input is transformed into a numerical format that the LLM can understand.
The user sends a text query (e.g., "What is the capital of France?").
Tokenization is the crucial step in which a large language model (LLM) breaks down raw text into smaller, manageable units called tokens. These tokens can be words, parts of words, or even single characters, depending on the tokenization method. Once the text is tokenized, each token is assigned a unique numerical ID from the model's vocabulary dictionary, which is what the LLM understands and processes. Each model has its own tokenization vocabulary dictionary that maps each token to a numerical value. You can examine this using https://tiktokenizer.vercel.app/
The LLM's tokenizer breaks down the text into smaller units called tokens. Tokens can be words, or characters. For example, "What is the capital of France?" might be tokenized into ['What', ' is', ' the', ' capital', ' of', ' France', '?'].
As we know, a computer can't perform mathematical operations on token IDs, as they're just arbitrary numbers. Once the raw input (prompt) is tokenized, the model converts each token into vector embeddings into a high-dimensional vector space. Each token is now represented by a long list of numbers (a vector) that captures its semantic meaning and relationships with other tokens. This also allows the model to understand the semantic meaning and intent of your query rather than just recognizing individual words. Unlike older methods, an LLM's vector embedding for a word like "apple" can change based on the sentence it's in. In "I ate an apple," the vector would be closer to "fruit," while in "I have an Apple computer," it would be closer to "technology." This contextual awareness is a cornerstone of modern LLMs.
A vector embedding is a numerical representation of an object, such as a word, sentence, or even an image, in a high-dimensional space. In the context of large language models (LLMs), these vectors are crucial because they transform human language into a format that computers can understand and process.
Think of an embedding as a point in a multidimensional map. This map is designed so that objects with similar meanings are located closer together. For example, the vector for "king" would be mathematically closer to the vector for "queen" than to the vector for "banana." This spatial relationship allows the LLM to understand semantic similarity and context, which is key to its ability to generate coherent and meaningful responses.
Instead of a simple one-to-one mapping (like a dictionary), an embedding captures a word's rich meaning, including its relationships to other words. The process of creating these embeddings is a core part of an LLM's training, where it learns to assign these numerical values based on the massive amounts of text it processes.
Positional encoding is a technique used in transformer models to give the model information about the position of each token in a sequence. Unlike traditional recurrent neural networks (RNNs) that process data sequentially, transformers process all tokens in a sequence simultaneously. This parallel processing makes them very efficient but also means they lose the crucial information about word order. Positional encoding solves this problem by adding a unique numerical vector to each token's embedding. This vector contains information about its position, which allows the model to understand syntax and the relative position of words.
Positional encoding assigns a unique vector to each time step in a sequence. The most common method uses sine and cosine functions to generate these vectors. This is preferred over a simple integer count (e.g., 1, 2, 3...) because it has two key advantages:
By adding these vectors to the token embeddings, the transformer model can distinguish between sentences like "The dog bit the man" and "The man bit the dog," which have the same words but completely different meanings due to word order.
The resulting vector now contains both the semantic meaning of the token and its positional information. This is the final numerical representation that is fed into the Transformer's attention and feed-forward layers.
During this phase, the model processes the encoded input to generate a response. This is the core of the LLM's work.
RAG (Retrieval-Augmented Generation) takes place during the inference phase, specifically as a preliminary step to the final output generation. It's an augmentation process that happens after the user provides their input but before the LLM begins to generate a response.
LLM generative model responds to a query with confidence based on its training and sometime the answer could be wrong because of lack of source or sometime the information is outdated and that is a major challenge the LLM models face.
To overcome this situation, the RAG framework jumps in. Now instead of just relying on what the LLM knows, RAG adds a content source (this could be open like internet or closed like collection of documents etc.) and instructs the LLM generative model to look at the content source before responding anything. Now the LLM talks to content store to retrieve the information that is relevant to user’s query. This way RAG augments the model with new information and model can answer the same questions quickly. RAG also enforces the model to pay attention to the primary source data before giving a response and in fact now being able to give evidence.
RAG (Retrieval-Augmented Generation) is a framework that sits on top of the core LLM process. It's an architecture or technique that augments the LLM's capabilities.
Think of LLM as a very smart student who only reads certain textbooks up to a specific date. The processes like tokenization, embedding, and positional encoding—are how the student reads and understands those textbooks.
RAG, in this analogy, is like giving the student a personal librarian. When a user asks a question, the librarian first goes out and finds the most relevant, up-to-date information from a separate, external library (a database or knowledge base). The librarian then provides this information to the student along with the original question. The student can now use this fresh, new context to formulate a much more accurate and comprehensive answer than they could have with just their existing knowledge.
Why RAG is a Separate Process
RAG is a distinct phase because it involves steps that happen outside the LLM's core model. The process typically looks like this:
RAG is an active, dynamic process that occurs in real-time for each user query. It's the key to making LLM’s responses more accurate, current, and verifiable without the need for expensive and time-consuming retraining.
This is the final stage where the LLM's numerical output is converted back into human-readable text.
